Risorsa
Valutazione della precisione dell'Copyleaks Rilevatore di intelligenza artificiale
Una metodologia passo dopo passo
Data del test: 25 maggio 2024
Modello testato: V5
Riteniamo che sia più importante che mai essere completamente trasparenti riguardo al rilevatore di intelligenza artificiale accuratezza, tassi di falsi positivi e falsi negativi, aree di miglioramento e altro ancora per garantire un uso e un'adozione responsabili. Questa analisi completa mira a garantire la piena trasparenza sulla metodologia di test del modello V5 del nostro rilevatore AI.
Metodologia
I team di Data Science e QA di Copyleaks hanno eseguito test in modo indipendente per garantire risultati imparziali e accurati. I dati di test differivano dai dati di addestramento e non contenevano contenuti precedentemente inviati al rilevatore AI per il rilevamento AI.
I dati dei test consistevano in testo scritto da persone provenienti da set di dati verificati e testo generato dall’intelligenza artificiale da vari modelli di intelligenza artificiale. Il test è stato eseguito con l'API Copyleaks.
Metrica
Le metriche includono la precisione complessiva basata sul tasso di identificazione del testo corretto ed errato, oltre al ROC-AUC (caratteristica operativa del ricevitore – Area sotto la curva), che esamina i tassi di veri positivi (TPR) e i tassi di falsi positivi (FPR). Ulteriori parametri includono il punteggio F1, il tasso di veri negativi (TNR), l'accuratezza e le matrici di confusione.
Risultati
I test verificano che il rilevatore AI mostri un'elevata precisione di rilevamento per distinguere tra testo scritto da esseri umani e testo generato dall'intelligenza artificiale, mantenendo al contempo un basso tasso di falsi positivi.
Processo di valutazione
Utilizzando un sistema a doppio dipartimento, abbiamo progettato il nostro processo di valutazione per garantire qualità, standard e affidabilità di massimo livello. Abbiamo due dipartimenti indipendenti che valutano il modello: i team di data science e QA. Ciascun dipartimento lavora in modo indipendente con i propri dati e strumenti di valutazione e non ha accesso al processo di valutazione dell'altro. Questa separazione garantisce che i risultati della valutazione siano imparziali, oggettivi e accurati, catturando al contempo tutte le possibili dimensioni delle prestazioni del nostro modello. Inoltre, è essenziale notare che i dati di test sono separati dai dati di addestramento e testiamo i nostri modelli solo su nuovi dati che non hanno visto in passato.
Metodologia
I team di QA e Data Science di Copyleaks hanno raccolto in modo indipendente una serie di set di dati di test. Ogni set di dati di test è costituito da un numero finito di testi. L'etichetta prevista, un indicatore che indica se un testo specifico è stato scritto da un essere umano o da un'intelligenza artificiale, di ciascun set di dati viene determinata in base alla fonte dei dati. I testi umani sono stati raccolti da testi pubblicati prima dell’avvento dei moderni sistemi di intelligenza artificiale generativa o successivamente da altre fonti attendibili che sono state nuovamente verificate dal team. I testi generati dall'intelligenza artificiale sono stati generati utilizzando una varietà di modelli e tecniche di intelligenza artificiale generativa.
I test sono stati eseguiti sull'API Copyleaks. Abbiamo verificato se l'output dell'API era corretto per ciascun testo in base all'etichetta di destinazione, quindi abbiamo aggregato i punteggi per calcolare la matrice di confusione.
Risultati: team di scienza dei dati
Il team di Data Science ha condotto il seguente test indipendente:
- La lingua dei testi era l'inglese e sono stati testati in totale 250.030 testi scritti da persone e 123.244 testi generati dall'intelligenza artificiale di vari LLM.
- Le lunghezze del testo variano, ma i set di dati contengono solo testi con lunghezze superiori a 350 caratteri, il minimo accettato dal nostro prodotto.
Metriche di valutazione
Le metriche utilizzate in questa attività di classificazione del testo sono:
1. Matrice di confusione: una tabella che mostra TP (veri positivi), FP (falsi positivi), TN (veri negativi) e FN (falsi negativi).
2. Accuratezza: la proporzione dei risultati veri (sia veri positivi che veri negativi) tra il numero totale di testi che sono stati controllati.
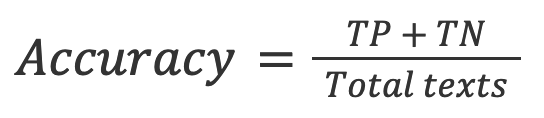
3. TNR: la proporzione delle previsioni negative accurate in tutte le previsioni negative.
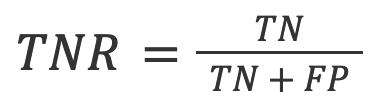
Nel contesto del rilevamento dell'intelligenza artificiale, TNR è l'accuratezza del modello sui testi umani.
4. TPR (noto anche come Recall): la percentuale di risultati veri positivi tutte le previsioni effettive.
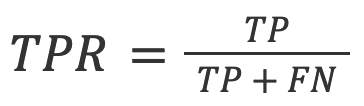
Nel contesto del rilevamento dell'intelligenza artificiale, il TPR è la precisione del modello sui testi generati dall'intelligenza artificiale.
5. Punteggio F-beta: Il media armonica ponderata tra precisione e richiamo, favorendo maggiormente la precisione (poiché vogliamo favorire un tasso di falsi positivi inferiore).
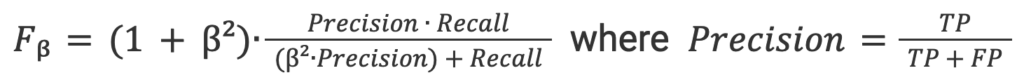
6. ROC-AUC: Valutazione del scambio tra TPR e FPR.
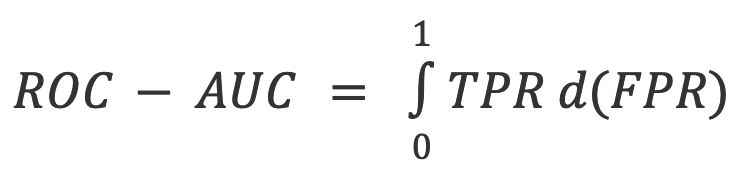
Set di dati combinati di intelligenza artificiale e umani
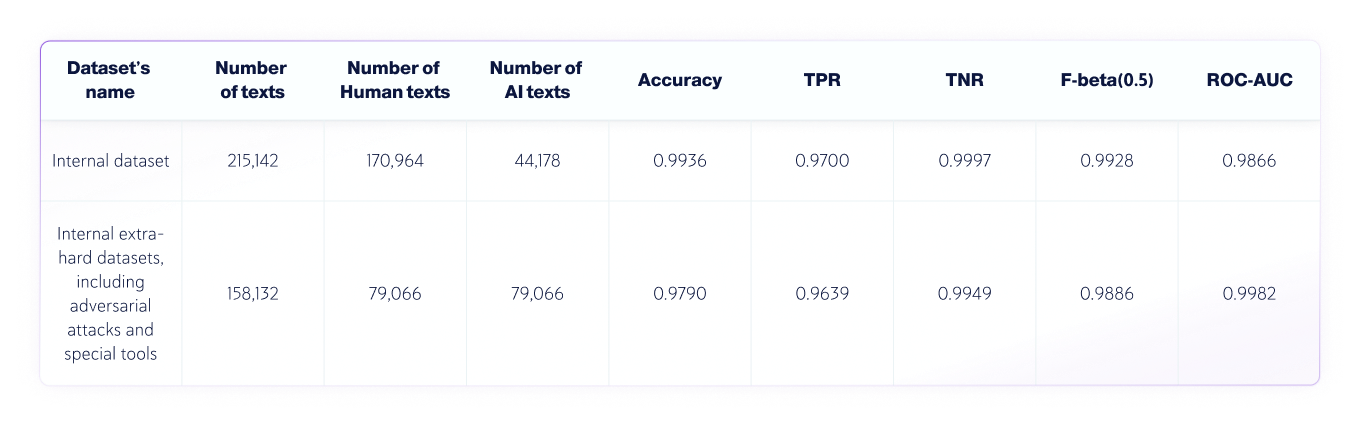
Risultati: team di controllo qualità
Il team QA ha condotto il seguente test indipendente:
- La lingua del testo era l'inglese e sono stati testati in totale 320.000 testi scritti da persone e 172.500 testi generati dall'intelligenza artificiale da vari LLM.
- Le lunghezze del testo variano, ma i set di dati contengono solo testi con lunghezze superiori a 350 caratteri, il minimo accettato dal nostro prodotto.
Set di dati riservati agli utenti umani
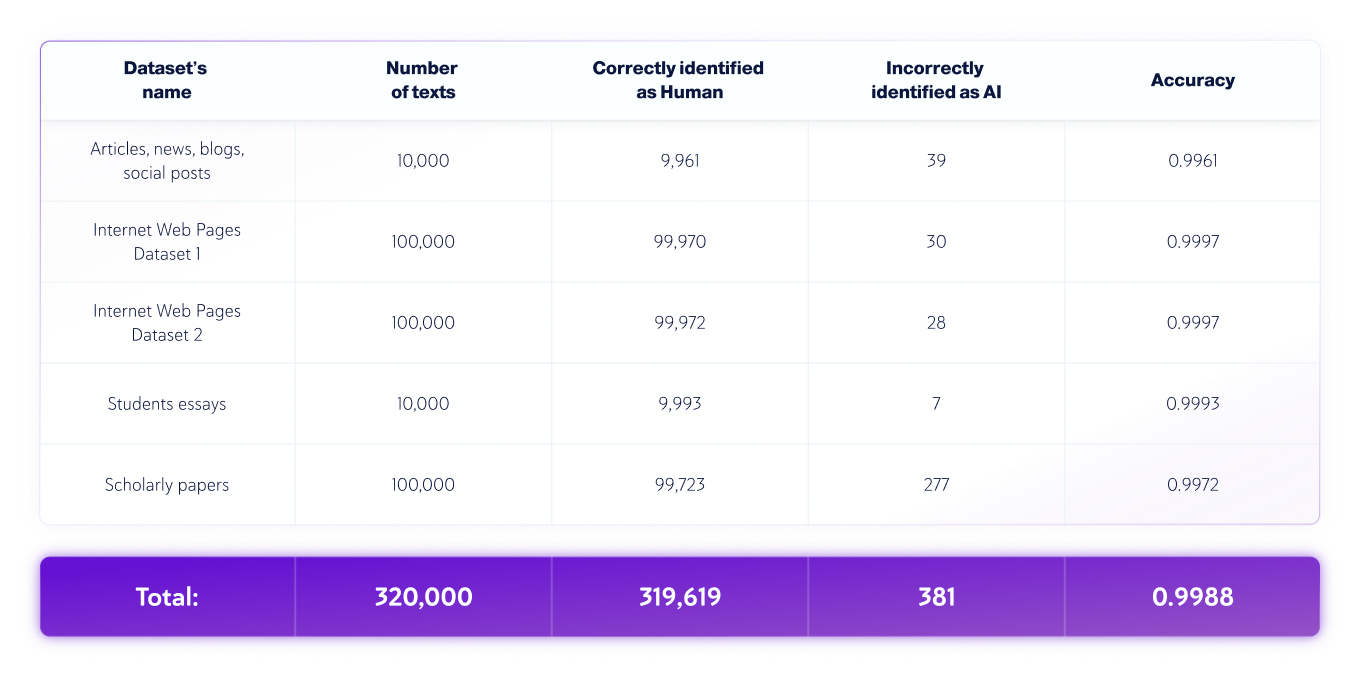
Set di dati solo AI
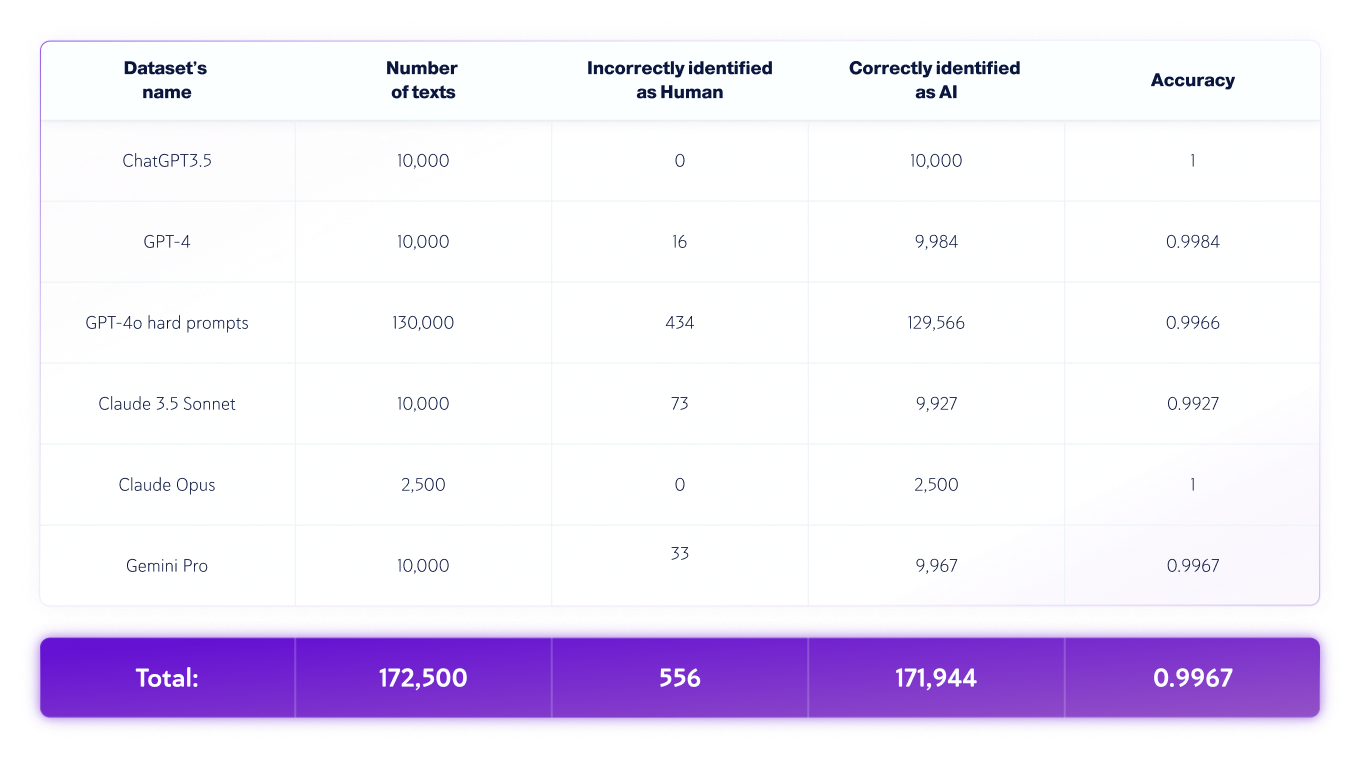
*Le versioni dei modelli possono cambiare nel tempo. I testi sono stati generati utilizzando una delle versioni disponibili dei modelli di intelligenza artificiale generativa di cui sopra.
Analisi degli errori di testo umani e AI
Durante il processo di valutazione, identifichiamo e analizziamo gli errori commessi dal modello e produciamo un rapporto dettagliato che consentirà al team di data science di correggere le cause alla base di questi errori. Ciò viene fatto senza esporre gli errori stessi al team di data science. Tutti gli errori vengono sistematicamente registrati e classificati in base al loro carattere e natura in un “processo di analisi delle cause profonde”, che mira a comprendere le cause sottostanti e identificare modelli ripetuti. Questo processo è sempre in corso, garantendo il miglioramento e l’adattabilità del nostro modello nel tempo.
Un esempio di tale test è la nostra analisi di dati Internet dal 2013 al 2024 utilizzando il nostro modello V4. WAbbiamo campionato 1 milione di testi ogni anno, a partire dal 2013, utilizzando eventuali falsi positivi rilevati dal 2013 al 2020, prima del rilascio dei sistemi di intelligenza artificiale, per contribuire a migliorare ulteriormente il modello.
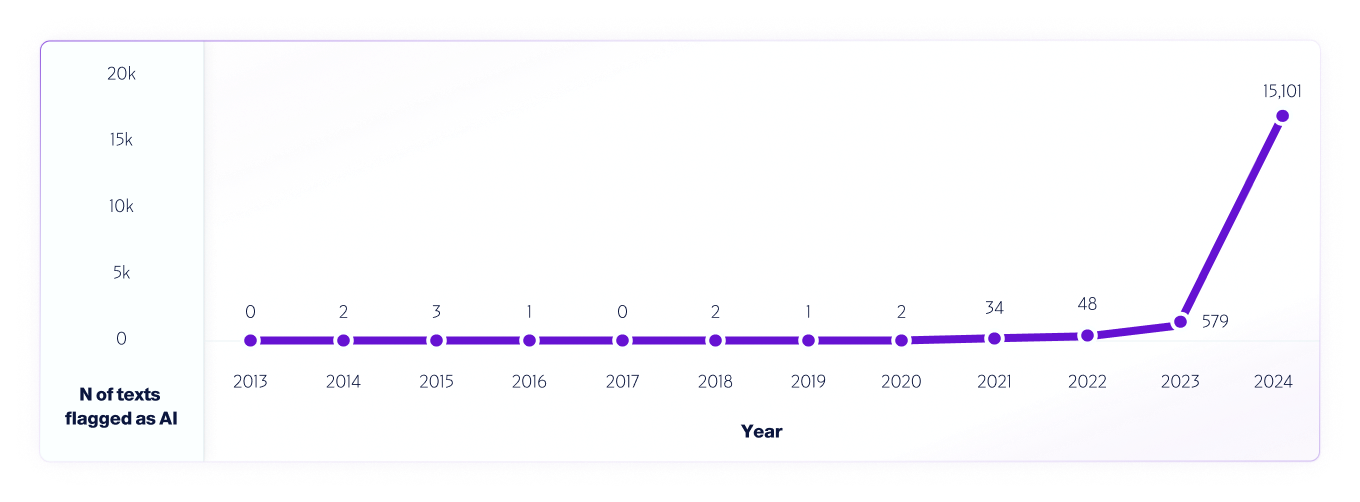
Simile a come ricercatori in tutto il mondo hanno e continuano a testare diverse piattaforme di rilevamento AI per valutarne le capacità e i limiti, incoraggiamo pienamente i nostri utenti a condurre test nel mondo reale. Infine, man mano che verranno rilasciati nuovi modelli, continueremo a condividere le metodologie di test, l'accuratezza e altre considerazioni importanti di cui essere consapevoli.