Ressource
Bewertung der Genauigkeit des Copyleaks KI-Detektor
Eine Schritt-für-Schritt-Methodik
Testdatum: 25. Mai 2024
Getestetes Modell: Version 5
Wir glauben, dass es wichtiger denn je ist, völlig transparent zu sein, was die Genauigkeit, die Rate falsch-positiver und falsch-negativer Ergebnisse, Verbesserungsbereiche und mehr, um eine verantwortungsvolle Nutzung und Übernahme sicherzustellen. Diese umfassende Analyse soll vollständige Transparenz hinsichtlich der Testmethodik unseres AI Detector-Modells V5 gewährleisten.
Methodik
Die Data Science- und QA-Teams von Copyleaks führten unabhängig voneinander Tests durch, um unvoreingenommene und genaue Ergebnisse sicherzustellen. Die Testdaten unterschieden sich von den Trainingsdaten und enthielten keinen Inhalt, der zuvor an den AI Detector zur KI-Erkennung übermittelt wurde.
Die Testdaten bestanden aus von Menschen geschriebenem Text aus verifizierten Datensätzen und KI-generiertem Text aus verschiedenen KI-Modellen. Der Test wurde mit der Copyleaks-API durchgeführt.
Metriken
Zu den Metriken gehören die Gesamtgenauigkeit basierend auf der Rate der korrekten und falschen Texterkennung sowie ROC-AUC (Receiver Operating Characteristic – Area Under the Curve), das die True-Positive-Raten (TPR) und False-Positive-Raten (FPR) untersucht. Weitere Metriken sind der F1-Score, die True-Negative-Rate (TNR), Genauigkeit und Konfusionsmatrizen.
Ergebnisse
Tests bestätigen, dass der AI Detector eine hohe Erkennungsgenauigkeit bei der Unterscheidung zwischen von Menschen geschriebenem und von KI generiertem Text aufweist und gleichzeitig eine niedrige Falsch-Positiv-Rate beibehält.
Bewertungsvorgang
Mithilfe eines Zwei-Abteilungen-Systems haben wir unseren Evaluierungsprozess so gestaltet, dass er höchste Qualität, Standards und Zuverlässigkeit gewährleistet. Wir haben zwei unabhängige Abteilungen, die das Modell evaluieren: die Data Science- und die QA-Teams. Jede Abteilung arbeitet unabhängig mit ihren Evaluierungsdaten und -tools und hat keinen Zugriff auf den Evaluierungsprozess der anderen. Diese Trennung stellt sicher, dass die Evaluierungsergebnisse unvoreingenommen, objektiv und genau sind und gleichzeitig alle möglichen Dimensionen der Leistung unseres Modells erfassen. Außerdem ist es wichtig zu beachten, dass die Testdaten von den Trainingsdaten getrennt sind und wir unsere Modelle nur mit neuen Daten testen, die sie in der Vergangenheit noch nicht gesehen haben.
Methodik
Die QA- und Data Science-Teams von Copyleaks haben unabhängig voneinander eine Vielzahl von Testdatensätzen gesammelt. Jeder Testdatensatz besteht aus einer begrenzten Anzahl von Texten. Die erwartete Bezeichnung – ein Marker, der angibt, ob ein bestimmter Text von einem Menschen oder von einer KI geschrieben wurde – jedes Datensatzes wird anhand der Datenquelle bestimmt. Menschliche Texte wurden aus Texten gesammelt, die vor dem Aufkommen moderner generativer KI-Systeme oder später von anderen vertrauenswürdigen Quellen veröffentlicht wurden, die vom Team erneut überprüft wurden. KI-generierte Texte wurden mithilfe einer Vielzahl von generativen KI-Modellen und -Techniken generiert.
Die Tests wurden mit der Copyleaks-API ausgeführt. Wir haben überprüft, ob die Ausgabe der API für jeden Text basierend auf dem Ziellabel korrekt war, und haben dann die Ergebnisse aggregiert, um die Konfusionsmatrix zu berechnen.
Ergebnisse: Data Science Team
Das Data Science-Team hat den folgenden unabhängigen Test durchgeführt:
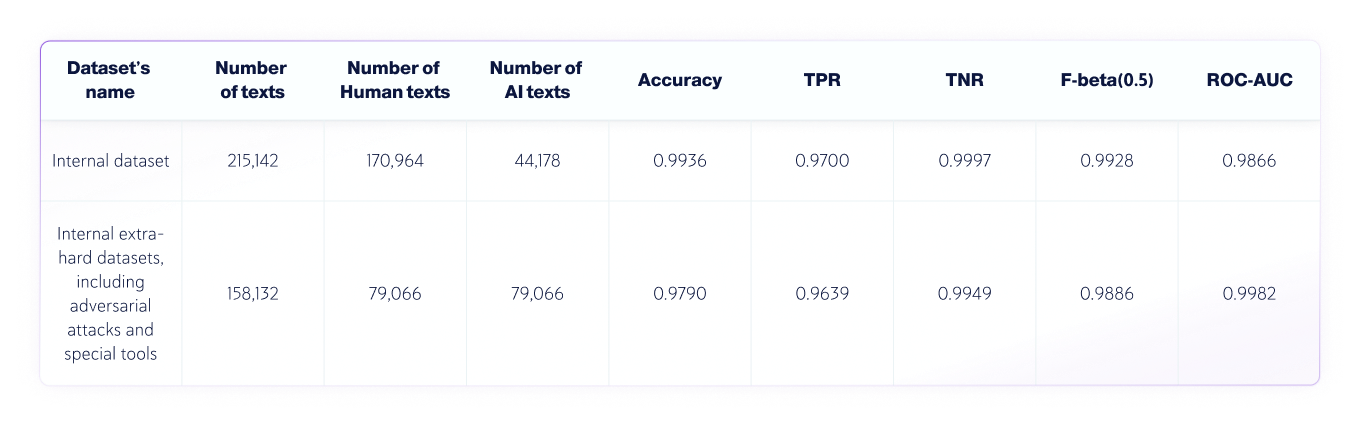
- Die Sprache der Texte war Englisch, und insgesamt wurden 250.030 von Menschen geschriebene Texte und 123.244 von KI generierte Texte aus verschiedenen LLMs getestet..
- Die Textlängen variieren, aber die Datensätze enthalten nur Texte mit einer Länge von mehr als 350 Zeichen – das Minimum, das unser Produkt akzeptiert.
Bewertungsmetriken
Die in dieser Textklassifizierungsaufgabe verwendeten Metriken sind:
1. Verwirrungsmatrix: Eine Tabelle, die TP (wahre Positive), FP (falsche Positive), TN (wahre Negative) und FN (falsche Negative) zeigt.
2. Genauigkeit: der Anteil der wahren Ergebnisse (sowohl wahre positive als auch wahre negative) unter die Gesamtzahl der Texte die überprüft wurden.
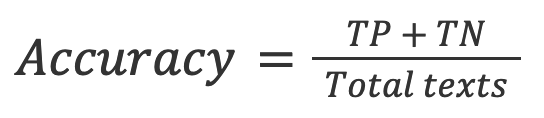
3. TNR: Der Anteil der genauen negativen Vorhersagen in alle negativen Vorhersagen.
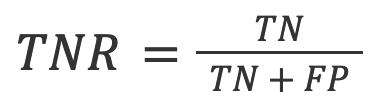
Im Kontext der KI-Erkennung ist TNR die Genauigkeit des Modells bei menschlichen Texten.
4. TPR (auch Recall genannt): Der Anteil der echten positiven Ergebnisse in alle tatsächlichen Vorhersagen.
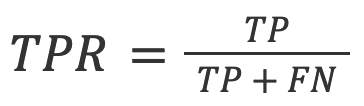
Im Kontext der KI-Erkennung ist TPR die Genauigkeit des Modells bei KI-generierten Texten.
5. F-Beta-Score: Der gewichtetes harmonisches Mittel zwischen Präzision und Rückruf, wobei die Präzision stärker im Vordergrund steht (da wir eine niedrigere Falsch-Positiv-Rate bevorzugen möchten).
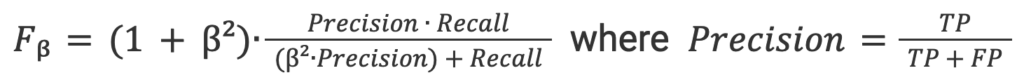
6. ROC-AUC: Bewertung der Abtausch zwischen TPR und FPR.
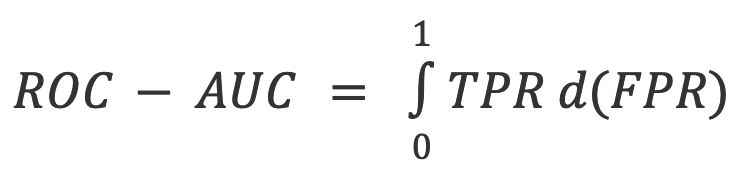
Kombinierte KI- und Human-Datensätze
Ergebnisse: QA-Team
Das QA-Team hat den folgenden unabhängigen Test durchgeführt:
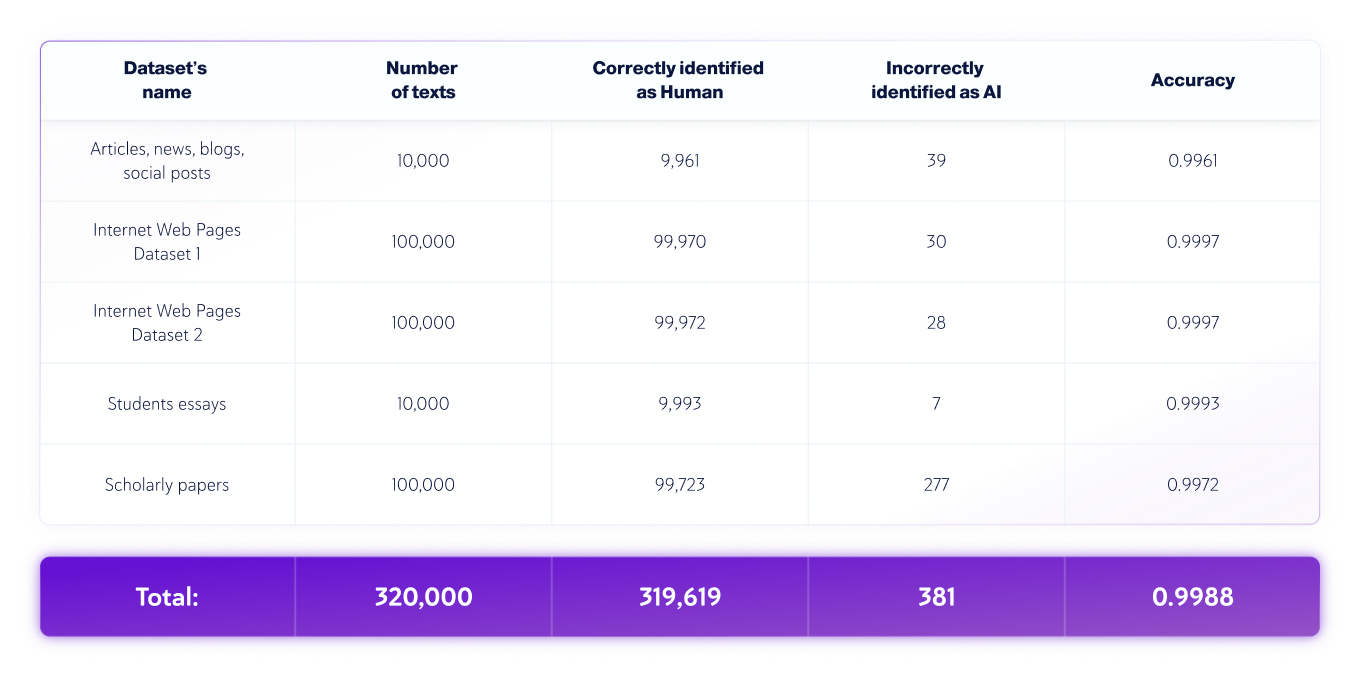
- Die Sprache des Textes war Englisch, und insgesamt wurden 320.000 von Menschen geschriebene Texte und 172.500 von KI generierte Texte aus verschiedenen LLMs getestet..
- Die Textlängen variieren, aber die Datensätze enthalten nur Texte mit einer Länge von mehr als 350 Zeichen – das Minimum, das unser Produkt akzeptiert.
Nur von Menschen erstellte Datensätze
Nur KI-Datensätze
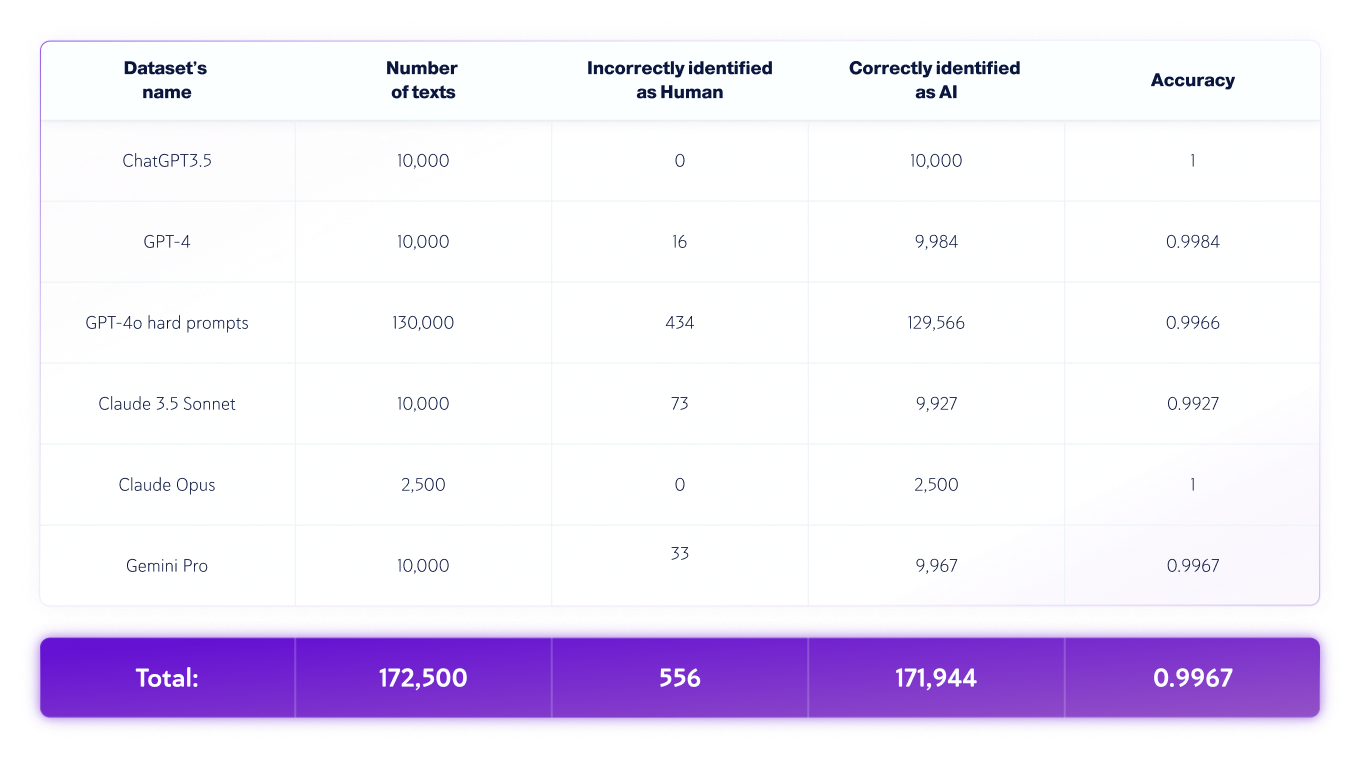
*Modellversionen können sich im Laufe der Zeit ändern. Texte wurden mit einer der verfügbaren Versionen der oben genannten generativen KI-Modelle generiert.
Menschliche und KI-basierte Textfehleranalyse
Während des Evaluierungsprozesses identifizieren und analysieren wir Fehler, die das Modell gemacht hat, und erstellen einen detaillierten Bericht, der es dem Data-Science-Team ermöglicht, die zugrunde liegenden Ursachen dieser Fehler zu beheben. Dies geschieht, ohne dass die Fehler selbst dem Data-Science-Team offengelegt werden. Alle Fehler werden systematisch protokolliert und basierend auf ihrem Charakter und ihrer Art in einem „Root-Cause-Analyseprozess“ kategorisiert, dessen Ziel es ist, die zugrunde liegenden Ursachen zu verstehen und sich wiederholende Muster zu identifizieren. Dieser Prozess ist ein fortlaufender Prozess, der die Verbesserung und Anpassungsfähigkeit unseres Modells im Laufe der Zeit gewährleistet.
Ein Beispiel für einen solchen Test ist Unsere Analyse von Internetdaten von 2013 bis 2024 mit unserem V4-Modell. WWir haben ab 2013 jedes Jahr eine Million Texte als Stichprobe genommen und dabei alle zwischen 2013 und 2020 (vor der Veröffentlichung der KI-Systeme) erkannten Falschmeldungen verwendet, um das Modell weiter zu verbessern.
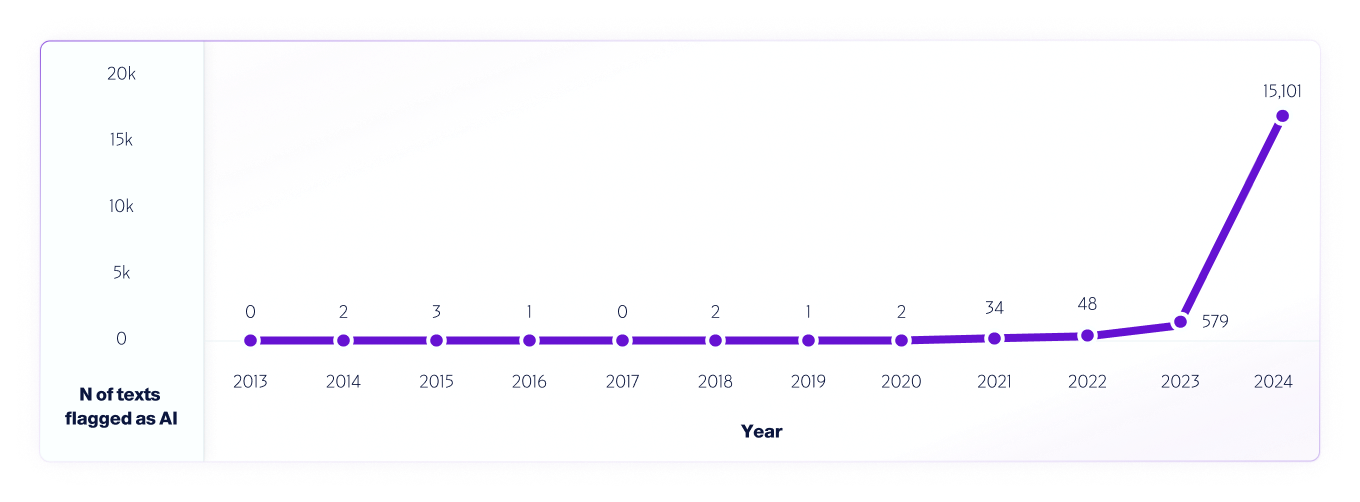
Ähnlich wie Forscher weltweit Wir haben verschiedene KI-Detektorplattformen getestet und tun dies auch weiterhin, um ihre Fähigkeiten und Grenzen zu ermitteln. Wir ermutigen unsere Benutzer daher ausdrücklich, Tests in der Praxis durchzuführen. Wenn neue Modelle auf den Markt kommen, werden wir weiterhin die Testmethoden, die Genauigkeit und andere wichtige Aspekte bekannt geben, die zu beachten sind.