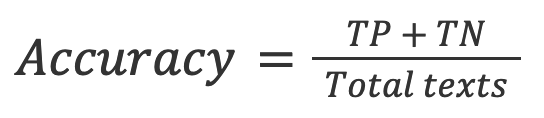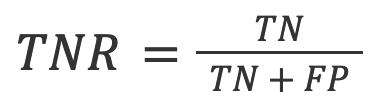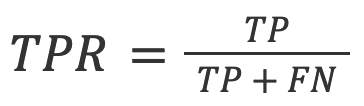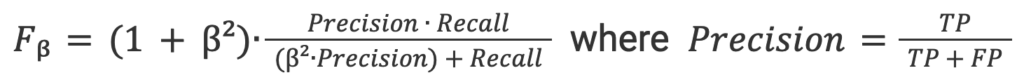全新改进!无论您在何处浏览,都可以使用下一代 AI 检测器扩展。
资源
测试日期: 2024 年 5 月 25 日
测试模型: V5
我们认为,AI Detector 的完全透明比以往任何时候都更加重要 准确性、误报率和漏报率、需要改进的地方等,以确保负责任地使用和采用。这项全面分析旨在确保我们的 AI Detector 的 V5 模型测试方法完全透明。
Copyleaks 数据科学和 QA 团队独立进行测试,以确保结果公正准确。测试数据与训练数据不同,且不包含之前提交给 AI Detector 进行 AI 检测的内容。
测试数据包括来自经过验证的数据集的人工书写文本和来自各种 AI 模型的 AI 生成文本。测试使用 Copyleaks API 进行。
指标包括基于正确和错误文本识别率的总体准确率,以及 ROC-AUC(接收者操作特性 - 曲线下面积),用于检查真阳性率 (TPR) 和假阳性率 (FPR)。其他指标包括 F1 分数、真阴性率 (TNR)、准确率和混淆矩阵。
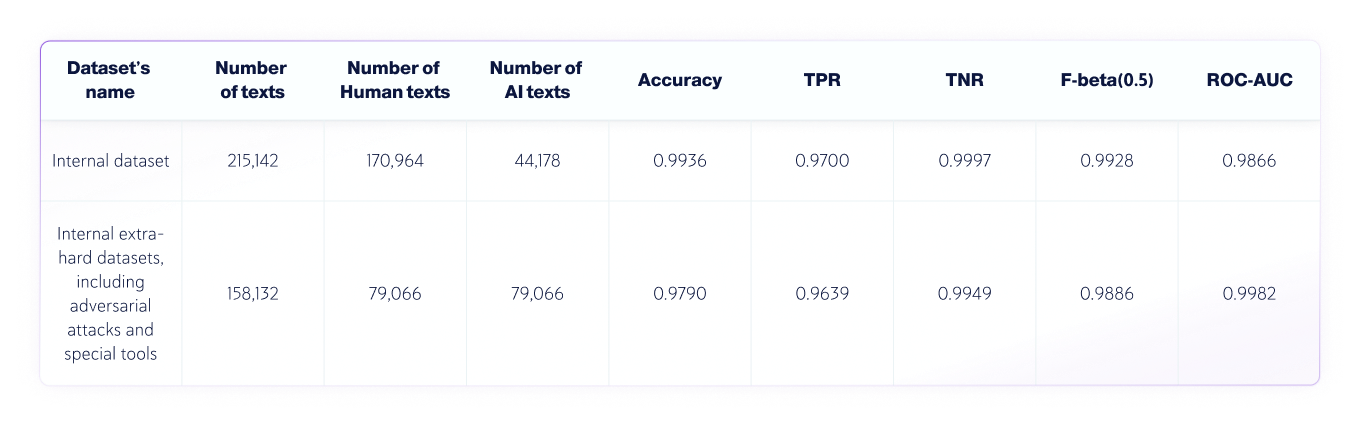
测试验证了 AI 检测器在区分人写文本和 AI 生成的文本方面表现出较高的检测准确率,同时保持较低的误报率。
我们采用双部门系统设计评估流程,以确保顶级质量、标准和可靠性。我们有两个独立的部门负责评估模型:数据科学团队和 QA 团队。每个部门都独立使用其评估数据和工具,无法访问对方的评估流程。这种分离确保评估结果公正、客观和准确,同时捕捉模型性能的所有可能维度。此外,必须注意的是,测试数据与训练数据是分开的,我们只使用模型过去从未见过的新数据来测试模型。
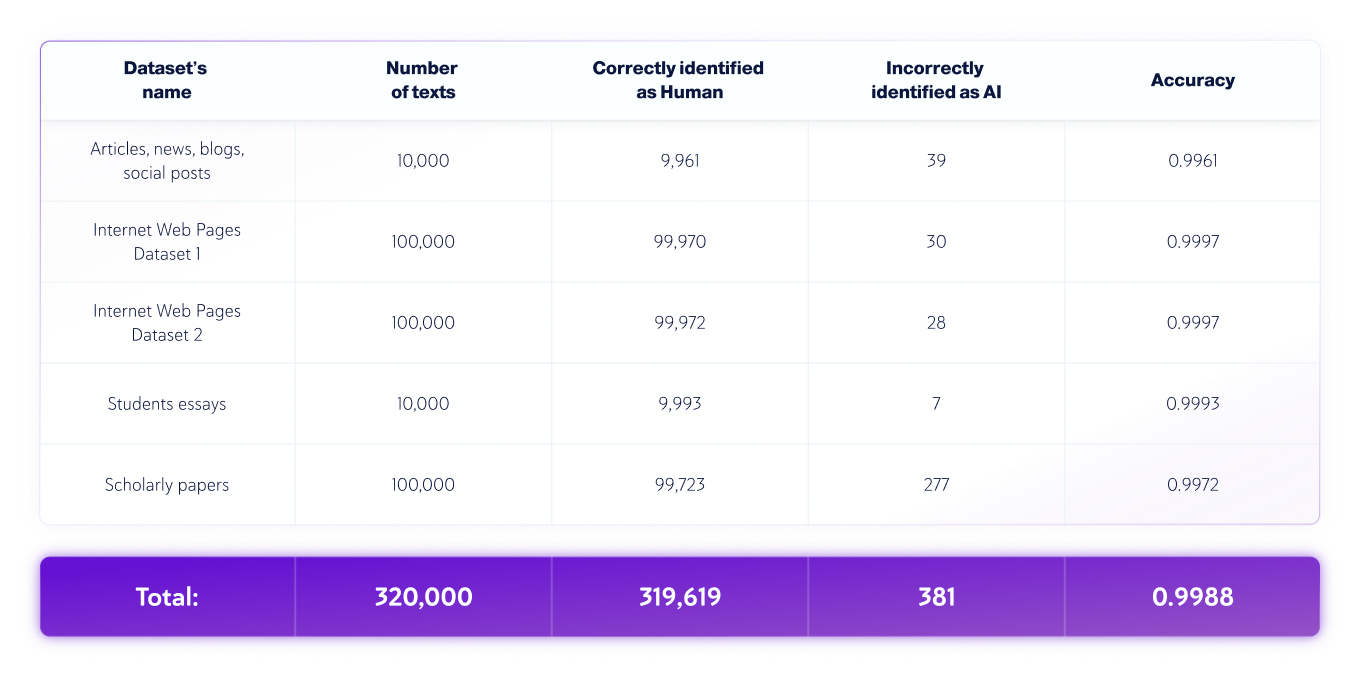
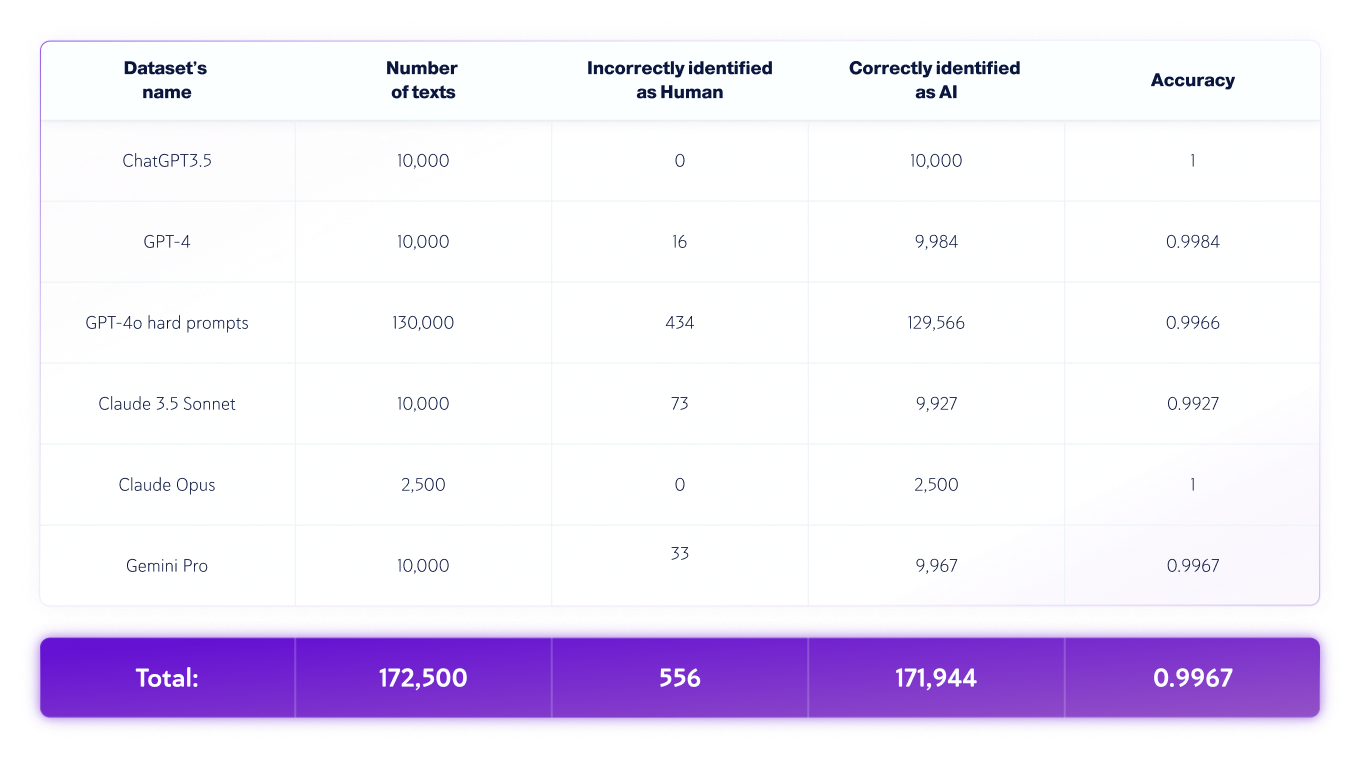
Copyleaks' QA 和数据科学团队独立收集了各种测试数据集。每个测试数据集由有限数量的文本组成。每个数据集的预期标签(指示特定文本是由人类还是人工智能编写的标记)是根据数据来源确定的。人类文本是从现代生成式人工智能系统兴起之前出版的文本中收集的,或者后来由团队再次验证的其他可信来源收集的。人工智能生成的文本是使用各种生成式人工智能模型和技术生成的。
测试针对 Copyleaks API 执行。我们根据目标标签检查 API 对每篇文本的输出是否正确,然后汇总分数以计算混淆矩阵。
数据科学团队进行了以下独立测试:
此文本分类任务中使用的指标是:
1. 混淆矩阵:显示 TP(真阳性)、FP(假阳性)、TN(真阴性)和 FN(假阴性)的表格。
2. 准确率:真实结果(真阳性和真阴性)的比例 文本总数 已检查。
3. TNR:准确负面预测的比例 所有负面预测.
在AI检测的背景下,TNR是模型对人类文本的准确率。
4. TPR(又称召回率):在 所有实际预测.
在AI检测的背景下,TPR是模型对AI生成文本的准确性。
5. F-beta 分数: 准确率和召回率之间的加权调和平均值,更倾向于准确率(因为我们希望获得较低的假阳性率).
6. ROC-AUC:评估 权衡 TPR 和 FPR 之间。
质量保证团队进行了以下独立测试:
*模型版本可能会随时间而变化。文本是使用上述生成式 AI 模型的可用版本之一生成的。
在评估过程中,我们会识别和分析模型的错误,并输出一份详细的报告,让数据科学团队能够纠正这些错误的根本原因。这个过程不会让数据科学团队知道错误本身。所有错误都会根据其特征和性质进行系统记录和分类,这是一个“根本原因分析过程”,旨在了解根本原因并识别重复的模式。这个过程一直在进行,确保我们的模型随着时间的推移不断改进和适应性。
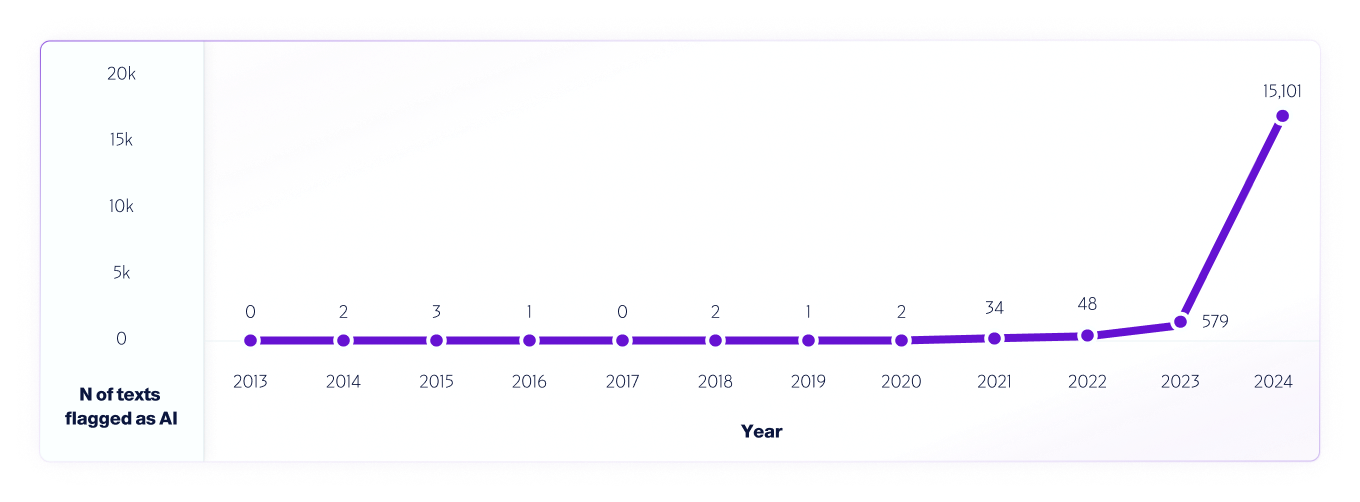
这种测试的一个例子是 我们的分析 使用我们的 V4 模型,2013 年至 2024 年的互联网数据。从 2013 年开始,我们每年都会抽取 100 万篇文本样本,使用在 AI 系统发布之前 2013 年至 2020 年检测到的任何误报来进一步改进模型。
类似于 世界各地的研究人员 我们已经并将继续测试不同的 AI 检测平台,以评估其能力和局限性,我们完全鼓励用户进行真实世界的测试。最终,随着新模型的发布,我们将继续分享测试方法、准确性和其他需要注意的重要事项。